

Semantic Alignment of Linguistic and Visual Understanding using Multi-modal Transformer
ARVR
JULY 1, 2022
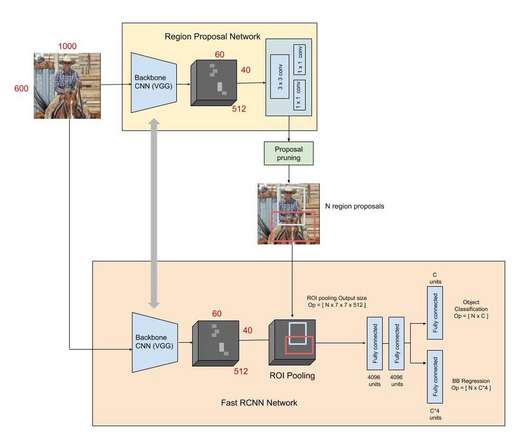
Pixel-BERT Pixel-BERT is a unified end-to-end framework that aligns the image pixels with text by deep multi-modal transformers that jointly learn visual and language embedding. Pixel-BERT which aligns semantic connection at the pixel and text level solves the limitation of region-based image feature extractors (e.g.,








































Let's personalize your content